4.5 使用统一内存的向量加法
发表于 2018-05-14 | 分类于 CUDA,Freshman | 评论数: 0 | 阅读次数:
Abstract: 使用统一内存的CUDA程序——向量加法
Keywords: 统一内存,Unified Memory
使用统一内存的向量加法
本文是前面关于统一内存内容的补充和实践,详细内容可以参考:内存管理
统一内存向量加法
统一内存的基本思路就是减少指向同一个地址的不同指针,比如我们经常见到的,在主机分配内存,然后传输到设备,然后再从设备传输回来,使用统一内存,就没有这些显式的需求了,而是由驱动程序帮我们完成。
具体的做法就是:
CHECK(cudaMallocManaged((void**)&a_d, nByte));
CHECK(cudaMallocManaged((void**)&b_d, nByte));
CHECK(cudaMallocManaged((void**)&res_d, nByte));
使用cudaMallocManaged来分配内存,这种内存在表面上看在设备和主机端都能访问,但是内部过程和我们前面手动复制来复制去是一样的,也就是内存复制是本质,而这个只是封装了一下。
我们来看看完整的代码:
#include <cuda_runtime.h>
#include <stdio.h>
#include "freshman.h"
void sumArrays(float * a, float * b, float * res, const int size)
{
for(int i = 0; i < size; i += 4)
{
res[i] = a[i] + b[i];
res[i+1] = a[i+1] + b[i+1];
res[i+2] = a[i+2] + b[i+2];
res[i+3] = a[i+3] + b[i+3];
}
}
__global__ void sumArraysGPU(float*a, float*b, float*res, int N)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if(i < N)
res[i] = a[i] + b[i];
}
int main(int argc, char **argv)
{
// set up device
initDevice(0);
int nElem = 1 << 24;
printf("Vector size:%d\n", nElem);
int nByte = sizeof(float) * nElem;
float *res_h = (float*)malloc(nByte);
memset(res_h, 0, nByte);
float *a_d, *b_d, *res_d;
CHECK(cudaMallocManaged((void**)&a_d, nByte));
CHECK(cudaMallocManaged((void**)&b_d, nByte));
CHECK(cudaMallocManaged((void**)&res_d, nByte));
initialData(a_d, nElem);
initialData(b_d, nElem);
// 使用统一内存,不需要显式的内存传输
//CHECK(cudaMemcpy(a_d, a_h, nByte, cudaMemcpyHostToDevice));
//CHECK(cudaMemcpy(b_d, b_h, nByte, cudaMemcpyHostToDevice));
dim3 block(512);
dim3 grid((nElem-1)/block.x+1);
double iStart, iElaps;
iStart = cpuSecond();
sumArraysGPU<<<grid, block>>>(a_d, b_d, res_d, nElem);
cudaDeviceSynchronize();
iElaps = cpuSecond() - iStart;
printf("Execution configuration<<<%d,%d>>> Time elapsed %f sec\n", grid.x, block.x, iElaps);
// 使用统一内存,不需要显式的内存传输
//CHECK(cudaMemcpy(res_from_gpu_h, res_d, nByte, cudaMemcpyDeviceToHost));
sumArrays(a_d, b_d, res_h, nElem);
checkResult(res_h, res_d, nElem);
// 统一内存使用cudaFree释放
cudaFree(a_d);
cudaFree(b_d);
cudaFree(res_d);
free(res_h);
return 0;
}
注意我们注释掉的部分,这就是省去的代码部分。
运行结果:
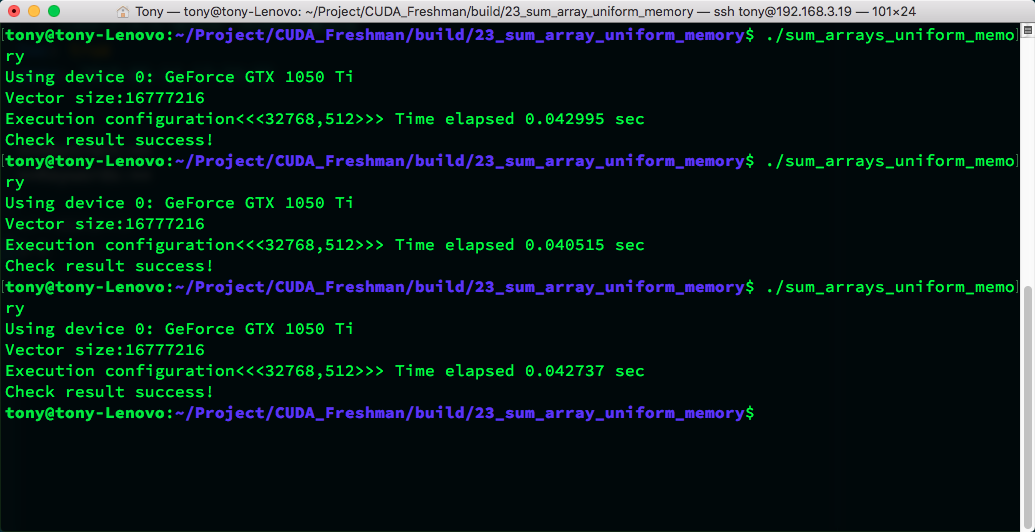
从这个代码而言,使用统一内存还是手动控制,运行速度差不多。
这里有一个新概念叫页面故障,我们分配的这个统一内存地址是个虚拟地址,对应了主机地址和GPU地址,当我们的主机访问这个虚拟地址的时候,会出现一个页面故障,当CPU要访问位于GPU上的托管内存时,统一内存使用CPU页面故障来触发设备到CPU的数据传输,这里的故障不是坏掉了,而是一种通信方式,类似于中断。
故障数和传输数据的大小直接相关。
使用:
nvprof --unified-memory-profiling per-process-device ./sum_arrays_unified_memory
可以查看到实际参数:
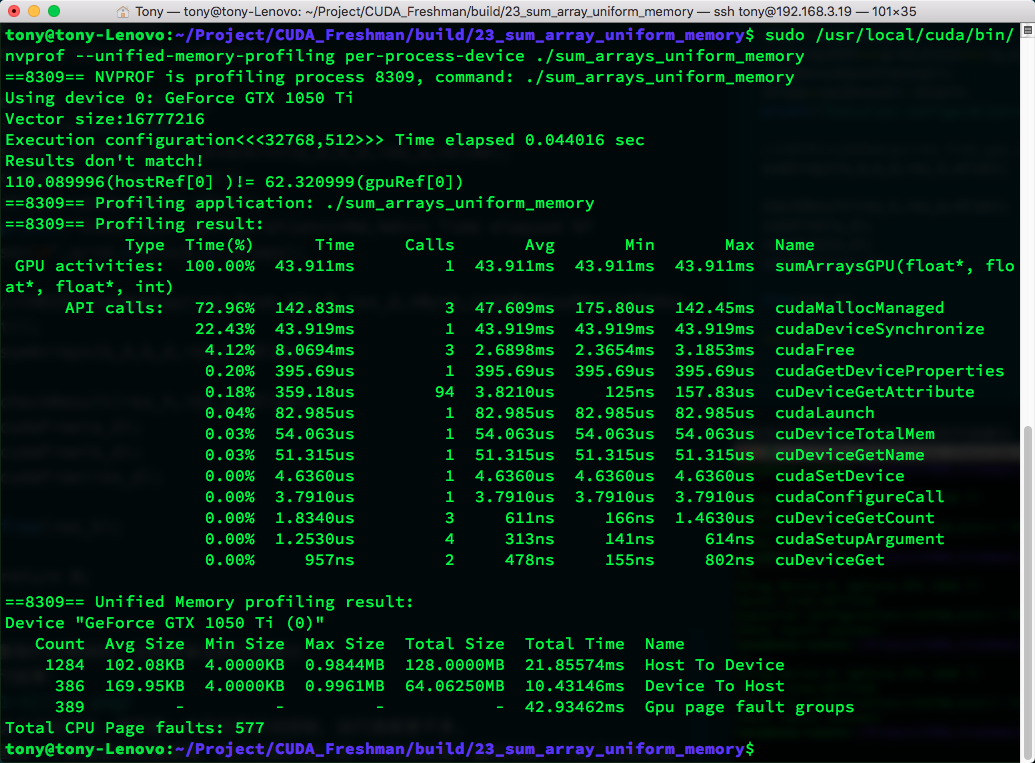
也可以使用nvvp来查看,效果类似。
统一内存的工作原理
统一内存的工作机制基于以下几个关键概念:
- 虚拟地址空间:统一内存提供了一个统一的虚拟地址空间,CPU和GPU都可以访问
- 按需迁移:数据在需要时自动在CPU和GPU之间迁移
- 页面故障处理:当访问不在当前设备上的数据时,触发页面故障,自动进行数据迁移
优势
- 编程简单:不需要显式管理CPU和GPU之间的数据传输
- 减少错误:避免了手动内存管理可能产生的错误
- 代码可读性:代码更简洁,逻辑更清晰
劣势
- 性能开销:页面故障和数据迁移可能带来额外开销
- 控制粒度:无法像手动管理那样精确控制数据传输时机
- 硬件要求:需要支持统一内存的GPU硬件
性能比较
在实际应用中,统一内存和手动内存管理的性能差异主要体现在:
- 数据访问模式:如果数据访问模式可预测,手动管理通常更高效
- 数据大小:对于小数据集,统一内存的便利性可能超过性能损失
- 算法复杂性:对于复杂的数据流,统一内存可以简化开发过程
总结
虽然统一内存管理给我们写代码带来了方便,而且在很多情况下速度也不错,但是实验表明,手动控制在性能上通常还是要优�于统一内存管理。换句话说,程序员的精确控制比编译器和目前设备的自动管理更有效率。
因此,在实际开发中建议:
- 原型开发阶段:使用统一内存快速验证算法正确性
- 性能优化阶段:考虑使用手动内存管理来获得最佳性能
- 平衡考虑:根据具体应用场景在开发效率和运行性能之间做出权衡
总的来说,统一内存是CUDA编程的一个重要发展方向,它降低了CUDA编程的门槛,但要获得最佳性能,深入理解和手动控制内存管理仍然是必要的。